By Dr. Martin Loetzsch and Krešimir Slugan
Providing users with a proper on-site search user experience is often one of the major technical challenges in building e-commerce websites. Although Elasticsearch is a fantastic search engine for the job, a lot of work needs to be done to adapt it to the specific business.
In this article, we will introduce a few Elasticsearch design patterns around our notion of usage-driven schemas that will help you to build a search so that:
Furthermore, we will introduce a technique for sorting search results which ranks products higher that:
And finally, we will illustrate how to personalize search experience using the example of dynamic pricing and discuss some other best practices. The examples will come from hammer2000.de, an online industrial and trade supply store that considers on-site search a major driver for its business. Please note that all examples are from early 2015 and have proven to work in Elasticsearch 1.x. Some queries will look different in Elasticsearch 2.x but the main concepts still hold true.
Finding products on e-commerce website can be tricky, even when you know exactly what you are looking for. Throughout this document, we will assume a customer wants to buy a hammer that weighs 2kg. A product that would meet his needs might be this “Fäustel” by Fortis:
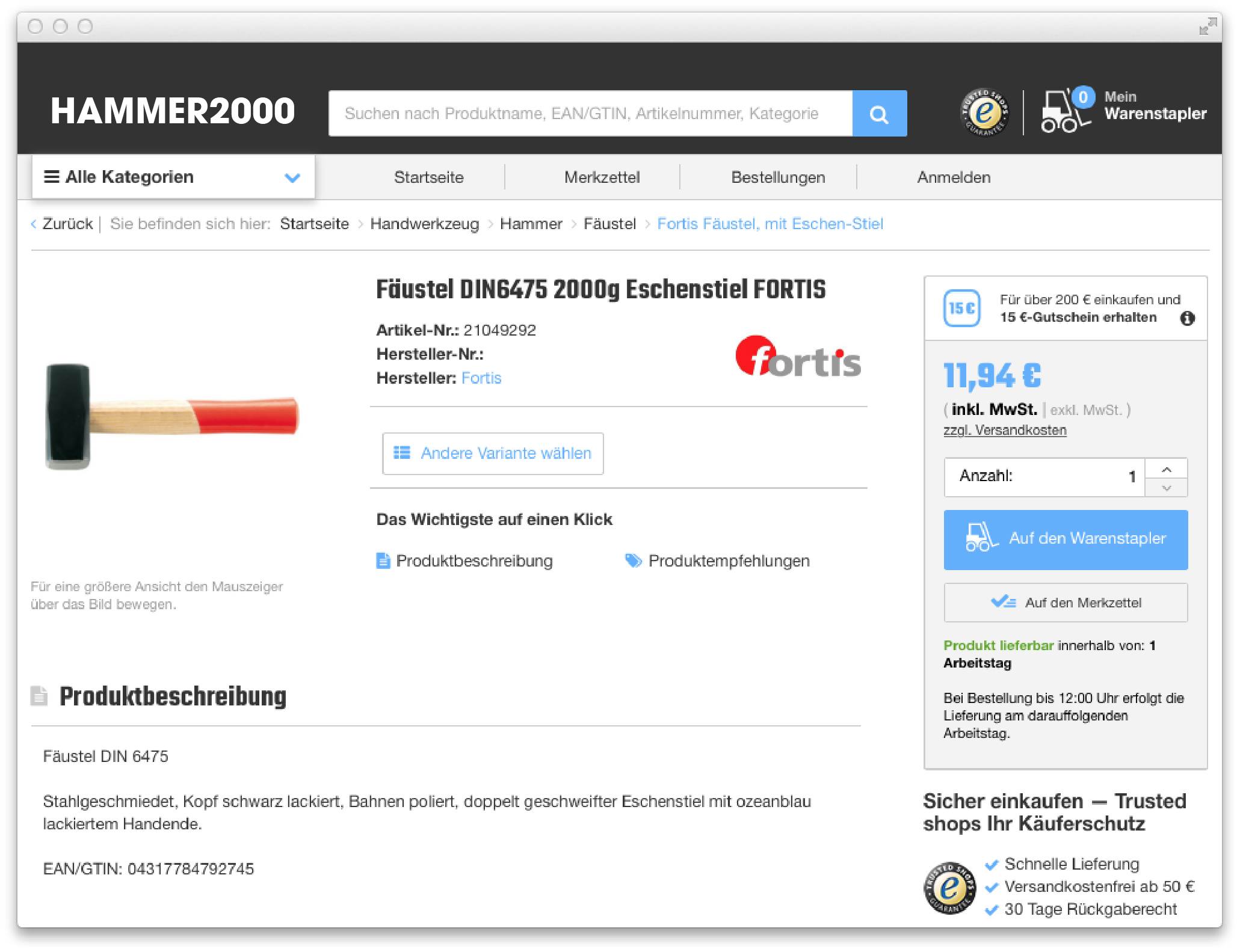
This is (most of) the search-relevant information that is known in the backend of Hammer2000 about the product above:
{
"name": "Fäustel DIN6475 2000g Eschenstiel FORTIS",
"staple-name": "Fortis Fäustel, mit Eschen-Stiel",
"description": "Fäustel DIN 6475<br><br>Stahlgeschmiedet, Kopf schwarz lackiert, Bahnen poliert, doppelt geschweifter Eschenstiel mit ozeanblau lackiertem Handende. SP11968 SP11968",
"preview_image": "faeustel-din6475-2000g-eschenstiel-fortis-21049292-0-JlHR5nOi-l.jpg",
"categories": [
"Fäustel",
"Handwerkzeug",
"Hammer",
"Fäustel"
],
"final_gross_price": 1149,
"final_net_price": 1003,
"url": "/handwerkzeug/fortis-faeustel-mit-eschen-stiel-SP11968",
"manufacturer": "Fortis",
"hammer_weight": 2000
}
Many tutorials recommend storing such documents “as is” into Elasticsearch, and the ease of doing so is indeed one of the core strengths of the platform. However, this approach has at least three quite serious drawbacks:
Elasticsearch queries need to “know” and explicitly list all the attributes that they want to use. For example a full-text search query would need to list all relevant text fields, a faceted search would need to list all possible filters.
Different usages of the same attribute require different handling, e.g. the category name “Hammer” needs to be indexed unaltered for filtering and completion, but fully analyzed for full-text search purpose.
The existence of “semantic” fields such as hammer_weight makes it hard to extend the product catalog: Whenever new product attributes are created, the Elasticsearch mapping needs to be extended.
The result is a huge complexity in query generation and schema management and this typically leads to situations where the full potential of available data is not used: full text search will operate only on some fields, and faceted navigation on others etc.
Both the schema and the query generator should not need to know that there is such a thing as as the weight of a hammer. We will argue for a document structure and schema design that is not built around the original data but around the usage of attributes in search operations.
At Hammer2000, this is how we send the same product as in the above example to Elasticsearch (don’t worry, we will explain the details later):
{
"type": "staple",
"search_result_data": {
"sku": "SP11968",
"name": "Fortis Fäustel, mit Eschen-Stiel",
"preview_image": "faeustel-din6475-2000g-eschenstiel-fortis-21049292-0-JlHR5nOi-l.jpg",
"number_of_products": "4",
"final_gross_price": "822",
"final_net_price": "691",
"base_gross_price": null,
"base_price_unit": null,
"url": "/handwerkzeug/fortis-faeustel-mit-eschen-stiel-SP11968"
},
"search_data": [
{
"full_text": " 21049289 4317784792714 04317784792714 Fäustel DIN 6475<br><br>Stahlgeschmiedet, Kopf schwarz lackiert, Bahnen poliert, doppelt geschweifter Eschenstiel mit ozeanblau lackiertem Handende. SP11968 SP11968",
"full_text_boosted": " Fortis Fäustel DIN6475 1000g Eschenstiel FORTIS 1000 Fäustel Handwerkzeug Hammer Fäustel Fortis Fäustel, mit Eschen-Stiel Fortis Fäustel, mit Eschen-Stiel",
"string_facet": [
{
"facet-name": "manufacturer",
"facet-value": "Fortis"
},
{
"facet-name": "hammer_weight",
"facet-value": "1000"
}
],
"number_facet": [
{
"facet-name": "final_gross_price",
"facet-value": 822
}
]
},
{
"full_text": " 21049290 4317784792721 04317784792721 Fäustel DIN 6475<br><br>Stahlgeschmiedet, Kopf schwarz lackiert, Bahnen poliert, doppelt geschweifter Eschenstiel mit ozeanblau lackiertem Handende. SP11968 SP11968",
"full_text_boosted": " Fortis Fäustel DIN6475 1250g Eschenstiel FORTIS 1250 Fäustel Handwerkzeug Hammer Fäustel Fortis Fäustel, mit Eschen-Stiel Fortis Fäustel, mit Eschen-Stiel",
"string_facet": [
{
"facet-name": "manufacturer",
"facet-value": "Fortis"
},
{
"facet-name": "hammer_weight",
"facet-value": "1250"
}
],
"number_facet": [
{
"facet-name": "final_gross_price",
"facet-value": 1020
}
]
},
{
"full_text": " 21049291 4317784792738 04317784792738 Fäustel DIN 6475<br><br>Stahlgeschmiedet, Kopf schwarz lackiert, Bahnen poliert, doppelt geschweifter Eschenstiel mit ozeanblau lackiertem Handende. SP11968 SP11968",
"full_text_boosted": " Fortis Fäustel DIN6475 1500g Eschenstiel FORTIS 1500 Fäustel Handwerkzeug Hammer Fäustel Fortis Fäustel, mit Eschen-Stiel Fortis Fäustel, mit Eschen-Stiel",
"string_facet": [
{
"facet-name": "manufacturer",
"facet-value": "Fortis"
},
{
"facet-name": "hammer_weight",
"facet-value": "1500"
}
],
"number_facet": [
{
"facet-name": "final_gross_price",
"facet-value": 1039
}
]
},
{
"full_text": " 21049292 4317784792745 04317784792745 Fäustel DIN 6475<br><br>Stahlgeschmiedet, Kopf schwarz lackiert, Bahnen poliert, doppelt geschweifter Eschenstiel mit ozeanblau lackiertem Handende. SP11968 SP11968",
"full_text_boosted": " Fortis Fäustel DIN6475 2000g Eschenstiel FORTIS 2000 Fäustel Handwerkzeug Hammer Fäustel Fortis Fäustel, mit Eschen-Stiel Fortis Fäustel, mit Eschen-Stiel",
"string_facet": [
{
"facet-name": "manufacturer",
"facet-value": "Fortis"
},
{
"facet-name": "hammer_weight",
"facet-value": "2000"
}
],
"number_facet": [
{
"facet-name": "final_gross_price",
"facet-value": 1194
}
]
}
],
"completion_terms": [
"Fortis",
"1000",
"1250",
"1500",
"2000",
"Fäustel",
"Handwerkzeug",
"Hammer",
"Fäustel"
],
"suggestion_terms": [
"Fortis Fäustel, mit Eschen-Stiel"
],
"number_sort": {
"final_gross_price": 822
},
"string_sort": {
"name": "Fortis Fäustel, mit Eschen-Stiel"
},
"scores": {
"top_seller": 0.91,
"pdp_impressions": 0.38,
"sale_impressions_rate": 0.8,
"data_quality": 0.87,
"delivery_speed": 0.85,
"random": 0.75,
"stock": 1
},
"category": {
"direct_parents": [
"bpka"
],
"all_parents": [
"bost",
"boum",
"boun",
"bpka"
],
"paths": [
"boum-boun-bpka"
]
},
"category_scores": {
"number_of_impressions": 265,
"number_of_orders": 23
}
}
That’s a lot of redundant information! For example the manufacturer, hammer_weight and name attributes are repeated in five top-level fields. But these attributes are used very differently in various search operations which require different analyzers and query strategies:
Search result rendering: The field search_result_data contains all the information that is returned as a result of a query for rendering a search result page or completion popup
Full-text search: The fields search_data/full_text and search_data/full_text_boosted contain all text content for which the product should be found in a full-text search
Faceted navigation: search_data/string_facet and search_data/number_facet contain all attributes for which search results should be grouped and filtered
Completion: completion_terms contains terms that should be shown as a completion as the user types a query
Spell checking: suggestion_terms contains terms that might be suggested as an alternative spelling when a user makes a typo
Static sorting: number_sort and string_sort are used for sorting by name or price
Dynamic result ranking: scores contains numeric indicators of user relevancy, past performance and product quality
Category navigation: category contains information about the position of a product in a category tree/graph
For reference, this is the complete schema (mapping) that we currently use to index pages at hammer2000 (again, we will explain most of the details later):
{
"page": {
"dynamic_templates": [
{
"search_result_data": {
"mapping": {
"type": "string",
"index": "no"
},
"path_match": "search_result_data.*"
}
},
{
"scores": {
"mapping": {
"type": "double"
},
"path_match": "scores.*"
}
},
{
"category_scores": {
"mapping": {
"type": "integer"
},
"path_match": "category_scores.*"
}
},
{
"category": {
"mapping": {
"type": "string",
"index": "not_analyzed"
},
"path_match": "category.*"
}
},
{
"string_sort": {
"mapping": {
"analyzer": "lowercase_keyword_analyzer",
"type": "string"
},
"path_match": "string_sort.*"
}
},
{
"number_sort": {
"mapping": {
"index": "not_analyzed",
"type": "double"
},
"path_match": "number_sort.*"
}
}
],
"properties": {
"search_data": {
"type": "nested",
"include_in_parent": false,
"properties": {
"full_text": {
"type": "string",
"index_analyzer": "full_text_index_analyzer",
"search_analyzer": "full_text_search_analyzer",
"fields": {
"no-decompound": {
"type": "string",
"index_analyzer": "full_text_index_analyzer_no_decompound",
"search_analyzer": "full_text_search_analyzer_no_decompound"
},
"no-stem": {
"type": "string",
"index_analyzer": "full_text_index_analyzer_no_stem",
"search_analyzer": "full_text_search_analyzer_no_stem"
}
}
},
"full_text_boosted": {
"type": "string",
"index_analyzer": "full_text_index_analyzer",
"search_analyzer": "full_text_search_analyzer",
"fields": {
"edge": {
"type": "string",
"index_analyzer": "full_text_edge_index_analyzer",
"search_analyzer": "full_text_search_analyzer"
},
"no-decompound": {
"type": "string",
"index_analyzer": "full_text_index_analyzer_no_decompound",
"search_analyzer": "full_text_search_analyzer_no_decompound"
},
"no-stem": {
"type": "string",
"index_analyzer": "full_text_index_analyzer_no_stem",
"search_analyzer": "full_text_search_analyzer_no_stem"
}
}
},
"string_facet": {
"type": "nested",
"properties": {
"facet-name": {
"type": "string",
"index": "not_analyzed"
},
"facet-value": {
"type": "string",
"index": "not_analyzed"
}
}
},
"number_facet": {
"type": "nested",
"properties": {
"facet-name": {
"type": "string",
"index": "not_analyzed"
},
"facet-value": {
"type": "double"
}
}
}
}
},
"completion_terms": {
"type": "string",
"analyzer": "completion_analyzer"
},
"suggestion_terms": {
"type": "string",
"index_analyzer": "term_suggestion_analyzer",
"search_analyzer": "lowercase_analyzer"
},
"type": {
"type": "string",
"index": "not_analyzed"
}
}
}
}
Faceted search (sometimes also called faceted navigation) allows users to navigate through a web site by applying filters for categories, attributes, price ranges and so on. It’s probably the most basic feature of a search and users expect this to work. Unfortunately, we observed that this is also one of the features that developers struggle with the most.
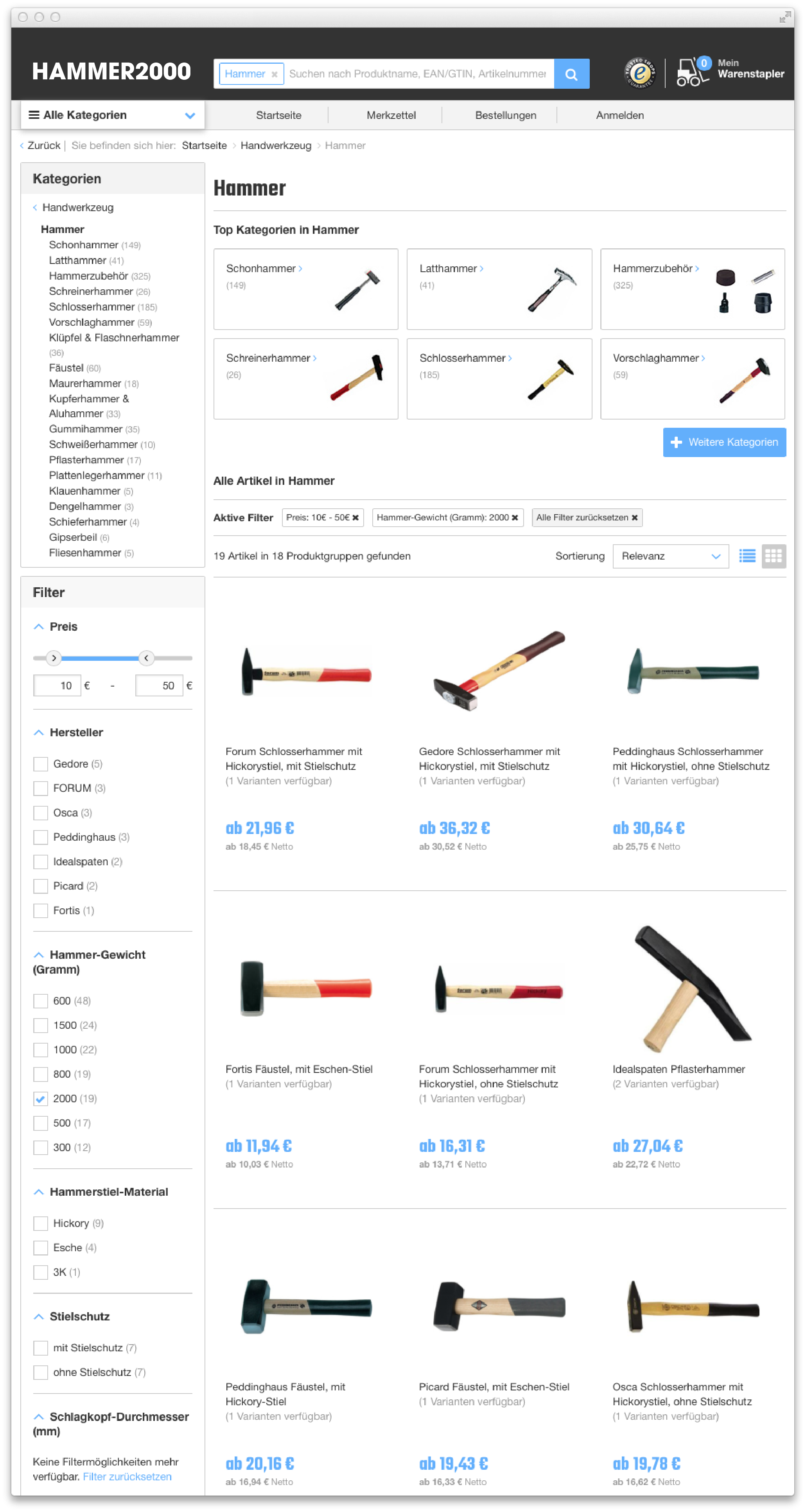
The main idea behind faceted search is to present the attributes of the documents of the previous search result as filters, which can be used by the user to narrow down search results. In the example below, a user clicked through the category tree to the “Hammer” category and then further filtered the results for documents with a hammer weight of 2000 grams and in a price range of 10€ to 50€. 19 documents were found, and the filter bar on the left lists those attributes that are contained in the search result along with a count of how many documents have the attribute (facet counts):
To support faceted search, Elasticsearch offers the simple but powerful concept of aggregations.
One of the nice features of aggregations is that they can be nested – in other words, it’s possible to define top-level aggregations that create “buckets” of documents and other aggregations that are executed inside those buckets on a subset of documents. The concept of aggregations is in general similar to the SQL GROUP_BY command (but much more powerful). Nested aggregations are analogous to SQL grouping but with multiple column names in the GROUP BY part of the query.
Before building aggregations, document attributes that can serve as facets need to be indexed in Elasticsearch. One way to index them would be to list all attributes and their values under the same field like in the following example:
"string_facets": {
"manufacturer": "Fortis",
"hammer_weight": "2000",
"hammer_color": "Red"
}
While this approach might be ok for filtering, it will not work well for faceting because queries would need to explicitly list all the field names for which we want to create aggregations. It can be done in two ways:
Always send all possible field names as part of your faceted query. This is not very practical when having 1000s of different facets. The query would become really big (and possibly slow) while the list of all possible field names would need to be maintained outside of Elasticsearch.
Run a first query that fetches the most common field names / attributes for a specific search request and then use those results to build a second query that does the faceting (and fetching of document). The second query would in that case look like this:
"aggregations": {
"facet_manufacturer": {
"terms": {
"field": "string_facets.manufacturer"
}
},
"facet_hammer_weight": {
"terms": {
"field": "string_facets.hammer_weight"
}
},
"facet_hammer_color": {
"terms": {
"field": "string_facets.hammer_color"
}
}
}
This will obviously not be very efficient in terms of speed (two queries) and will add additional complexity in query building and handling.
We instead suggest to separate the names and values of facets in documents sent to Elasticsearch like this:
"string_facets": [
{
"facet-name": "manufacturer",
"facet-value": "Fortis"
},
{
"facet-name": "hammer_weight",
"facet-value": "2000"
},
{
"facet-name": "hammer_color",
"facet-value": "Red"
}
]
This requires a special treatment in the mapping, because otherwise Elasticsearch will internally flatten and save them as follows:
"string_facets": {
"facet-name": ["manufacturer", "hammer_weight", "hammer_color"],
"facet-value": ["Fortis", "2000", "Red"]
}
Aggregations would in this case provide incorrect results because the relation between the specific attribute name and it’s values is lost. Therefore, facet fields need to be marked as “type”: “nested” in the Elasticsearch mapping:
"string_facets": {
"type": "nested",
"properties": {
"facet-name": {
"type": "string",
"index": "not_analyzed"
},
"facet-value": {
"type": "string",
"index": "not_analyzed"
}
}
}
Filtering and aggregating a structure like this requires nested filters and nested aggregations in queries.
Aggregation:
"aggregations": {
"agg_string_facet": {
"nested": {
"path": "string_facets"
},
"aggregations": {
"facet_name": {
"terms": {
"field": "string_facets.facet-name"
},
"aggregations": {
"facet_value": {
"terms": {
"field": "string_facets.facet-value"
}
}
}
}
}
}
}
Filter:
"filter": {
"nested": {
"path": "string_facets",
"filter": {
"bool": {
"must": [
{
"term": {
"string_facets.facet-name": "hammer_weight"
}
},
{
"terms": {
"string_facets.facet-value": [
"2000"
]
}
}
]
}
}
}
}
Numeric attributes need to be handled differently in aggregations and they have to be stored and analyzed separately. This is because numeric facets sometimes have huge numbers of distinct values. Instead of listing all possible values, it is sufficient to just get the minimum and maximum values and show them as a range selector or slider in the front end. This is possible only if values are stored as numbers.
The most important numeric facet on any e-commerce website is probably the price facet.
Document:
"number_facet": [
{
"facet-name": "final_gross_price",
"facet-value": 1194
}
]
Mapping:
"number_facet" : {
"type": "nested",
"properties": {
"facet-name": {
"type": "string",
"index": "not_analyzed"
},
"facet-value": {
"type": "double"
}
}
}
The aggregation of numeric facets uses the keyword "stats" instead of "terms" in queries. Unlike the "terms" aggregation that returns only the number of the term’s occurrences, "stats" returns statistical values like minimum, maximum and average:
"agg_number_facet": {
"nested": {
"path": "number_facet"
},
"aggs": {
"facet_name": {
"terms": {
"field": "number_facet.facet-name"
},
"aggs": {
"facet_value": {
"stats": {
"field": "number_facet.facet-value"
}
}
}
}
}
}
With this approach to faceted navigation, it is possible to render search result pages with a single Elasticsearch query and without having to know the list of available facets at query time. The additional effort in document preparation and query building immediately pays off because the solution automatically scales to thousands of facets.
Sometimes e-commerce websites support specific facet behaviour that let users select multiple values of the same facet on the front-end (e.g using checkbox). Check this stackoverflow discussion to see how to implement queries that supports this feature within the approach discussed here.
Also, you can have a look at a series of articles starting here for a much more detailled explanation of the approach discussed in this section.
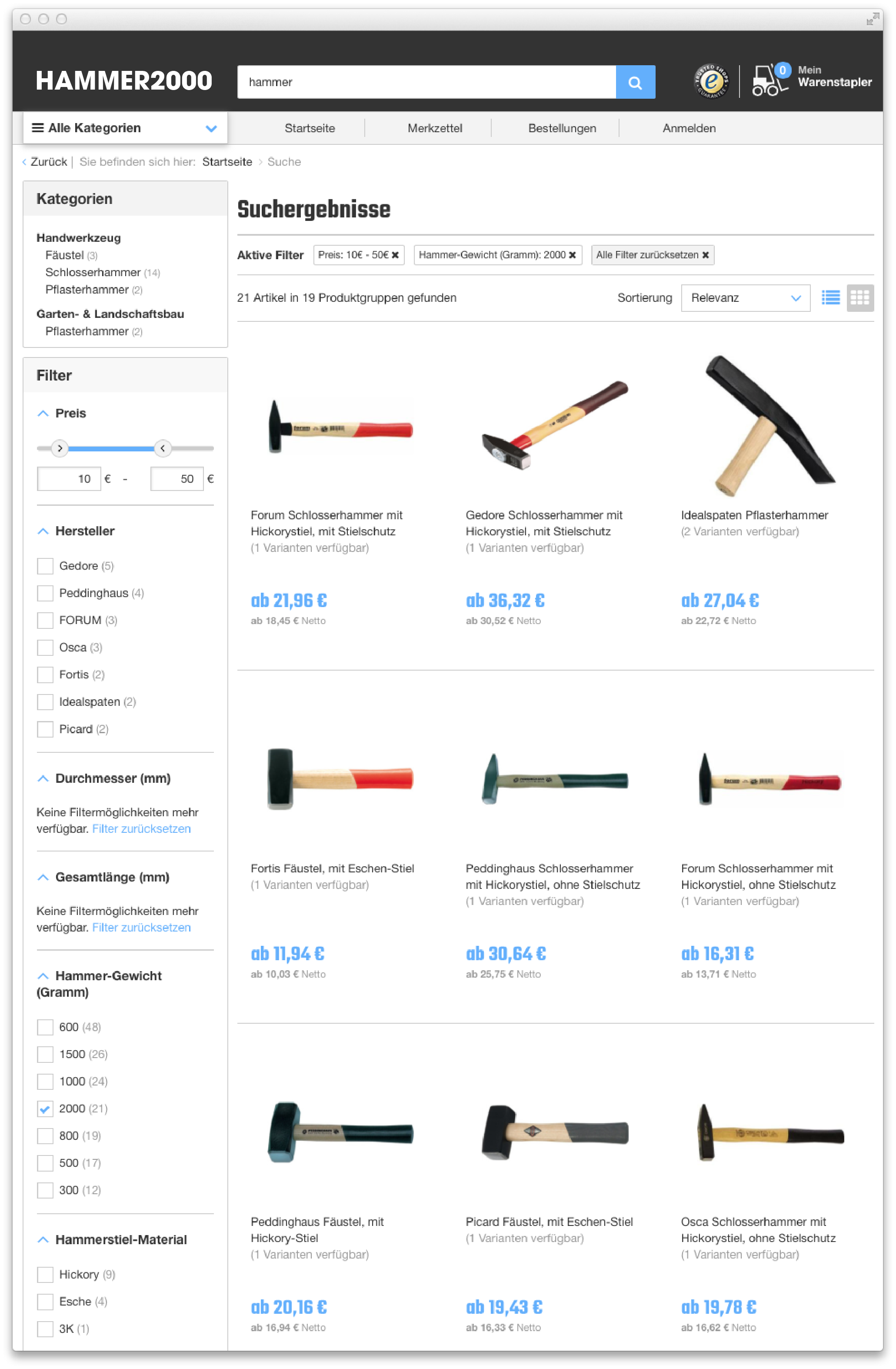
Full-text search is a feature where a user enters arbitrary text into a search field and then gets documents that are relevant for that query. It is normally combined with faceted navigation. In the example below, a user searched for “hammer” and then further filtered for hammer weights of 2000 gram and prices between 10€ and 50€:
Although some tweaking is necessary, Elasticsearch does a great job in running full-text queries fast (it’s one of the most important features of the underlying Lucene engine). On the other hand, more work is required to get text relevance right and to make sure that the first returned query results are the ones that are most relevant for the user.
The defaults of Elasticsearch work fine for basic full-text search use cases, but language- and business-dependent text processing needs to be performed for a great search experience. This is called text analysis and refers to the process of splitting source text into a stream of tokens. The Elasticsearch analysis module offers a set of pre-built default analyzers but it’s also possible to build custom ones.
Analyzers are composed of a single tokenizer and zero or more token filters. A tokenizer splits source text into a stream of tokens (e.g. splitting by whitespace characters) which are then passed to token filters. Filters are applied one by one, each modifying its input stream by deleting/splitting/changing tokens and passing the stream to the next filter. The resulting list of tokens is saved to Elasticsearch inverted index and made searchable in a very performant way.
The picture below shows a text analysis process that works good for tool-related text in German:

The exact steps and their order will differ for different business models and applications (there is no “free lunch” here) so this will require some experimentation before getting it right.
Text analysis is executed both for documents that are indexed to Elasticsearch and for search terms entered by the user. Index time and search time analyzers are often very similar but not necessarily the same. The analyzer above is an example of an index time analyzer, the corresponding search time analyzer has the same tokenizer and filters except the synonym and decompounder filter.
With a naive product-centric approach text analyzers would have to be added to all fields that contain text material (e.g. name, description, category-names, manufacturer, etc.). Moreover, all those attributes would need to be addressed separately in queries. This leads to unnecessarily complicated queries and, more importantly, requires additional effort when new data needs to be added to the documents. More text material per document usually means better search results and thus the process of adding new data to the index should be straightforward and simple.
We recommend putting all searchable text data for a document in one of the only two full-text document fields full-text and full-text-boosted, with more important attributes such as product names, brands and selected facets into the latter:
"full_text": "21049291 4317784792738 Fäustel DIN 6475<br><br>Stahlgeschmiedet, Kopf schwarz lackiert, Bahnen poliert, doppelt geschweifter Eschenstiel mit ozeanblau lackiertem Handende SP11968",
"full_text_boosted": "Fortis Fäustel DIN6475 2000g Eschenstiel FORTIS 2000 Fäustel Handwerkzeug Hammer Fäustel Fortis Fäustel, mit Eschen-Stiel Fortis Fäustel, mit Eschen-Stiel"
The boosting of the second field happens at query time, for example by multiplying base relevance with 7 for full_text_boosted and with 2 for full_text:
"multi_match": {
"fields": [
"search_data.full_text_boosted^7",
"search_data.full_text^2"
],
"type": "cross_fields",
"analyzer": "full_text_search_analyzer",
"query": "hammer"
}
Text relevance can be further improved by adding different analyzers for full-text fields. This is straightforward in Elasticsearch and requires small changes in the document mapping:
"properties": {
"full_text": {
"type": "string",
"index_analyzer": "full_text_index_analyzer",
"search_analyzer": "full_text_search_analyzer",
"fields": {
"no-decompound": {
"type": "string",
"index_analyzer": "full_text_index_analyzer_no_decompound",
"search_analyzer": "full_text_search_analyzer_no_decompound"
},
"no-stem": {
"type": "string",
"index_analyzer": "full_text_index_analyzer_no_stem",
"search_analyzer": "full_text_search_analyzer_no_stem"
}
}
}
}
Note: full_text_index_analyzer, full_text_search_analyzer, etc. are all examples of custom analyzers and need to be configured separately from the mapping.
Elasticsearch is now going to take a textual field (in this case full_text) and analyze it with three different analyzers: once with normal full_text_search_analyzer but also with two other analyzers that are skipping the decompounding and stemming analysis steps.
The reason for this is that the text loses some information during the analysis process (e.g. lowercasing the word removes the case information of the original word). By indexing the same text with different analyzers we have a chance to distinguish good matches from bad ones by giving higher scores to those search terms that match a higher number of analyzers.
Below is an example of a query that will
{
"query": {
"bool": {
"must": [
{
"multi_match": {
"fields": [
"search_data.full_text_boosted^7",
"search_data.full_text^2"
],
"operator": "AND",
"type": "cross_fields",
"analyzer": "full_text_search_analyzer",
"query": "hammer"
}
}
],
"should": [
{
"multi_match": {
"fields": [
"search_data.full_text_boosted.no-stem^7",
"search_data.full_text.no-stem^2"
],
"operator": "OR",
"type": "cross_fields",
"analyzer": "full_text_search_analyzer_no_stem",
"query": "hammer"
}
},
{
"multi_match": {
"fields": [
"search_data.full_text_boosted.no-decompound^7",
"search_data.full_text.no-decompound^2"
],
"operator": "OR",
"type": "cross_fields",
"analyzer": "full_text_search_analyzer_no_decompound",
"query": "hammer"
}
}
]
}
}
}
Term completion is a feature where a user gets suggestions for search terms and matching search results as he types the query. We call a completion multi-term when it is able to combine terms from different attributes in an open-ended fashion. In the below example, a user entered “fortis” (a brand) and started typing “hammer” (a category):

After completing “hammer”, the search would suggest more terms found in documents containing both “fortis” and “hammer”.
The Elasticsearch API offers the completion suggester, which works great in many cases but has one major drawback in that it can only suggest fixed terms that are saved to Elasticsearch during index time. So in the example above, the terms “fortis” and “hammer” as well as both compound variations, i.e. “fortis hammer” and “hammer fortis”, would have to be indexed.
We therefore recommend indexing all terms for which you want to offer auto completion (category names, facet values, brands and other categorial terms) in one field called completion_terms:
"completion_terms": [
"Fortis",
"1000",
"1250",
"1500",
"2000",
"Fäustel",
"Handwerkzeug",
"Hammer"
]
The field is analyzed with a very simple analyzer, which is based on the Elasticsearch keyword tokenizer (the analyzer is only used to remove some stop words).
"completion_terms": {
"type": "string",
"analyzer": "completion_analyzer"
}
In order to have products match partial search terms (like “fortis ham”), we apply an edge_ngram filter to a field that contains the same data as completion_terms. Only documents that match the current search query are considered when building auto completion terms. Auto completion terms are fetched by aggregating on the completion_terms field and showing terms with the highest number of occurrences. All of this is happening in one query. The aggregation part of that query (the part used for autocompletion) looks as follows:
"aggs": {
"autocomplete": {
"terms": {
"field": "completion_terms",
"size": 100
}
}
}
The main benefit of this approach is that it is possible to continuously suggest new terms as a user types. The main drawback is speed–The out-of-the-box completion suggester is much more optimized for speed.
Spelling suggestions provide the users with alternative search terms when the search query does not return any results:
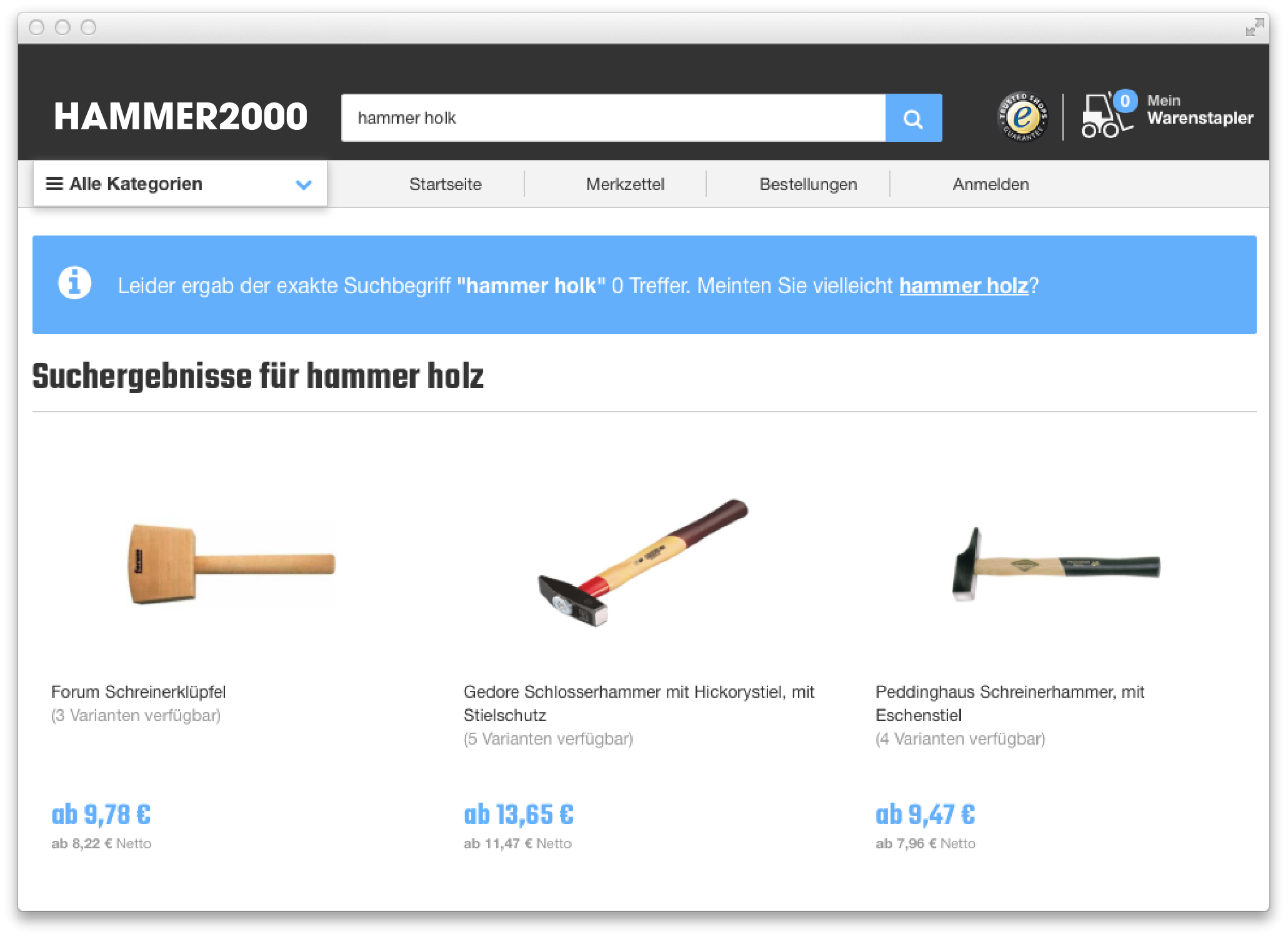
Translation: Unfortunately there were 0 results for your exact search term “hammer holk”. Did you possibly mean hammer holz?
This is one of the simplest features you can build with Elasticsearch and also one that your users expect to see. Elasticsearch has a highly configurable term suggester, which enables suggestions based on the edit distance between indexed terms and search terms.
We recommend putting all attributes that are suitable for spelling suggestions (i.e. short strings such as product and category names where you are sure that they are spelled correctly) into a single document field:
"suggestion_terms": [
"Fortis Fäustel, mit Eschen-Stiel"
]
Suggestion terms are then indexed by splitting them by whitespace and lowercasing. The same goes for search terms that will be compared with the indexed terms.
"suggestion_terms" : {
"type" : "string",
"analyzer" : "term_suggestion_analyzer",
}
At query time, a suggest part is added to every query. It will try to return the closest tokens (based on edit distance) for all terms that were not matched in the query. For tokens that match at least one document, no suggestions are going to be calculated. In case you have doubts about the quality of the suggestion_terms, it’s possible to fetch several suggestions per term from Elasticsearch and then use some heuristics in the back end to select one that exhibits a good combination of distance score and term frequency.
"suggest": {
"spelling-suggestion": {
"text": "hammmer",
"term": {
"field": "suggestion_terms",
"size": 1
}
}
}
When a query returns hundreds or thousands of results, it is absolutely crucial that the products at the top of the search result page are the ones that are most relevant to the user. Getting this right will lead to a higher conversion probability and increase customer happiness. Implementing proper data-driven ranking, however, is usually very tricky, because there might be large numbers of heuristics, which define what a good search result for a certain query is.
A common solution is to manually assign ranks to products (sometimes even within categories). However, this approach is not practical for large catalogs and might result in a bad search experience (for example, when products that are out of stock are listed at the top due to their manually assigned rank).
We recommend an approach where we pre-compute a list of normalized scores per product at import time and include them in the documents that are sent to Elasticsearch. These are the scores from our hammer example above (we left out the interesting scores due to the sensitivity of this information):
"scores": {
"top_seller": 0.91,
"pdp_impressions": 0.38,
"sale_impressions_rate": 0.8,
"data_quality": 0.87,
"delivery_speed": 0.85,
"random": 0.75,
"stock": 1
}
Each of these scores embodies a specific heuristic taken into account to define what a “good” product is; with higher values meaning “better”:
| Score | Basis for computation |
|---|---|
top_seller |
The number of products sold in the last three months |
pdp_impressions |
The number of product detail page impressions in the last three months |
sale_impressions_rate |
The conversion rate of the product in the last three months |
data_quality |
The quality of the product data (descriptions, images, etc.) |
delivery_speed |
How fast we expect the product to be delivered |
random |
A random number, included in rankings to avoid over-optimization |
stock |
1 if on stock, 0.001 if not, used to push out-of-stock products towards the end of the search results |
Many of these scores obviously only make sense for the business model of Hammer2000 (and we left out the interesting ones). Finding meaningful scores is one of the bigger challenges with respect to good ranking.
In the mapping, scores are indexed as non-analyzed numbers with this dynamic template:
"dynamic_templates": [
{
"scores": {
"mapping": {
"index": "not_analyzed",
"type": "double"
},
"path_match": "scores.*"
}
}
]
In queries, search results are sorted using an algebraic expression that combines these scores (we replaced the actual weights by random values):
{
"query": {
"filtered": {
"query": {
"function_score": {
"score_mode": "first",
"boost_mode": "replace",
"query": {},
"functions": [
{
"script_score": {
"script": "
(1 + _score ** 0.5)
* doc['scores.stock'].value
* (0.1 * doc['scores.random'].value
+ 0.3 * doc['scores.top_seller'].value
+ 0.1 * doc['scores.pdp_impressions'].value
+ 0.2 * doc['scores.sale_impressions_rate'].value
+ 0.1 * doc['scores.data_quality'].value
+ 0.3 * doc['scores.delivery_speed'].value)
"
}
]
}
}
}
}
}
This formula
puts quite some emphasis on a high relevance (the _score term, a measure that Elasticsearch provides to determine how closely a document matches the query),
requires the product to be in stock (by multiplying everything else with the scores.stock score),
and finally computes a weighted sum of the rest of the scores.
Very different kinds of scoring functions are conveivable and the advantages of combining scores at query time are twofold: Our stake holders (category and product managers) can help us in finding good formulas by testing the effect of different expressions on the sorting of actual queries at run-time. Second, it is possible to use different ranking strategies on different parts of the website.
To be able to combine scores in such expressions, we normalize them between 0 and 1 and try to make sure that they are more or less equally distributed across all documents. If, for example, the ranking formula is 0.3 * score_1 + 0.7 * score_2 and the scores are in the same range, then you could say that score_1 has a 30% influence on the outcome of the sorting and score_2 an influence of 70%. The equal distribution is important because if, for example, most documents have a very high score_2, then having a high score_2 becomes much more important for appearing at the top of the ranking than having a high score_1 (an effect which can be consciously used).
So for finding good normalization functions, it is important to look at the distribution of some measures across all products. This is the distribution of the number of sold items per product at Hammer2000 (numbers are only up to the end of 2014 due to data sensitivity):
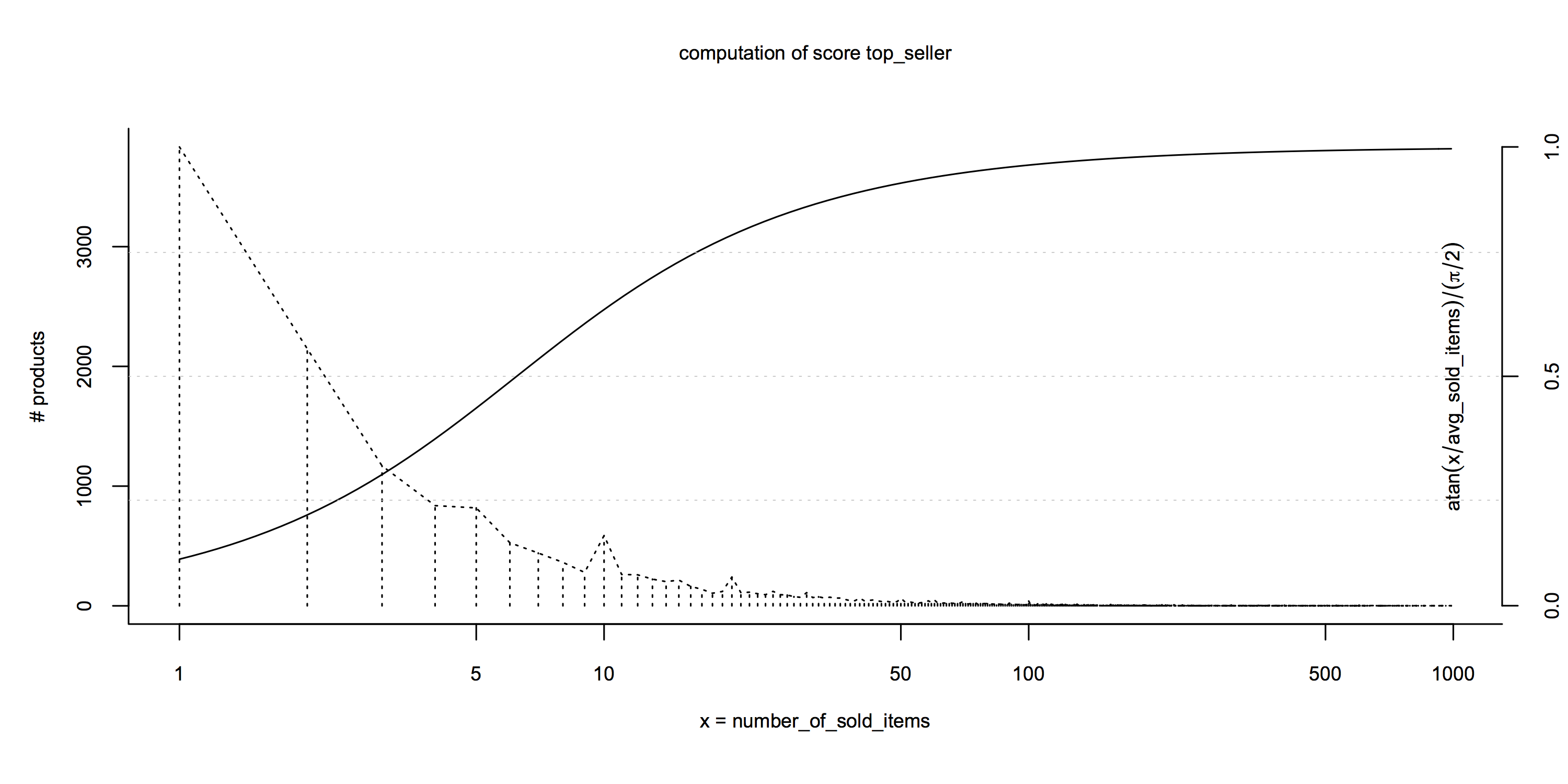
Out of the products sold at all, most were sold only once or twice, while only very few products were sold more than 10 times. For the top_seller score to be meaningful, it is less important whether the product sold 500 or 50 times but rather whether it sold 10 times or once. The atan(x - avg(X)) / (π / 2) score formula reflects this: it returns 0.5 for the average number of sold items across all products and has most of its dynamics around that average.
A second example is the distribution of the expected margin across products (again with data up to the end of 2014):
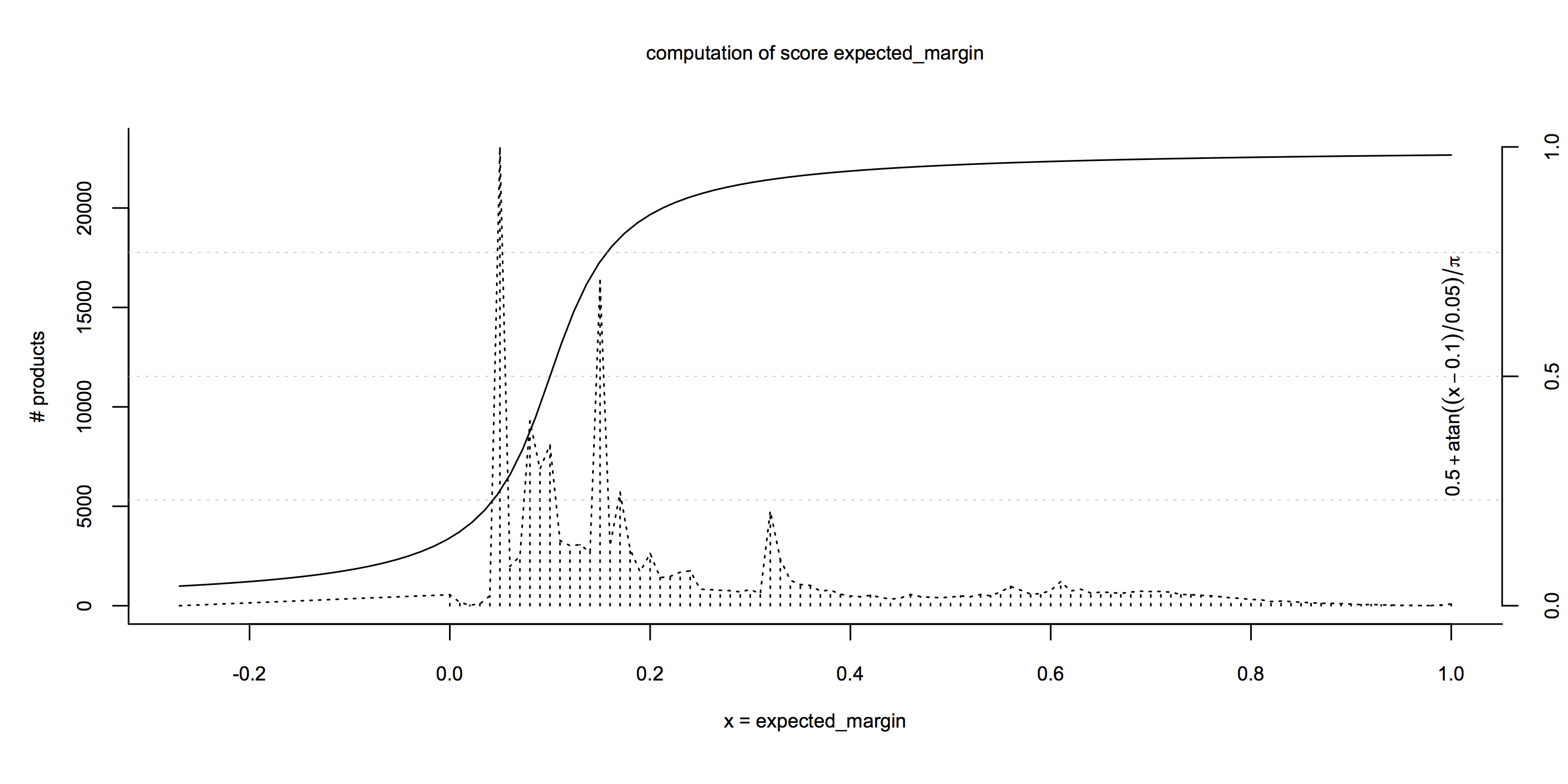
For such “Gaussian-looking” distributions, we also use functions that put the average at 0.5 and that have most of their dynamics within the standard deviation of the distribution: 0.5 + atan((x - avg(X)) / stdev(X)) / π.
The last example is the expected delivery time in hours:
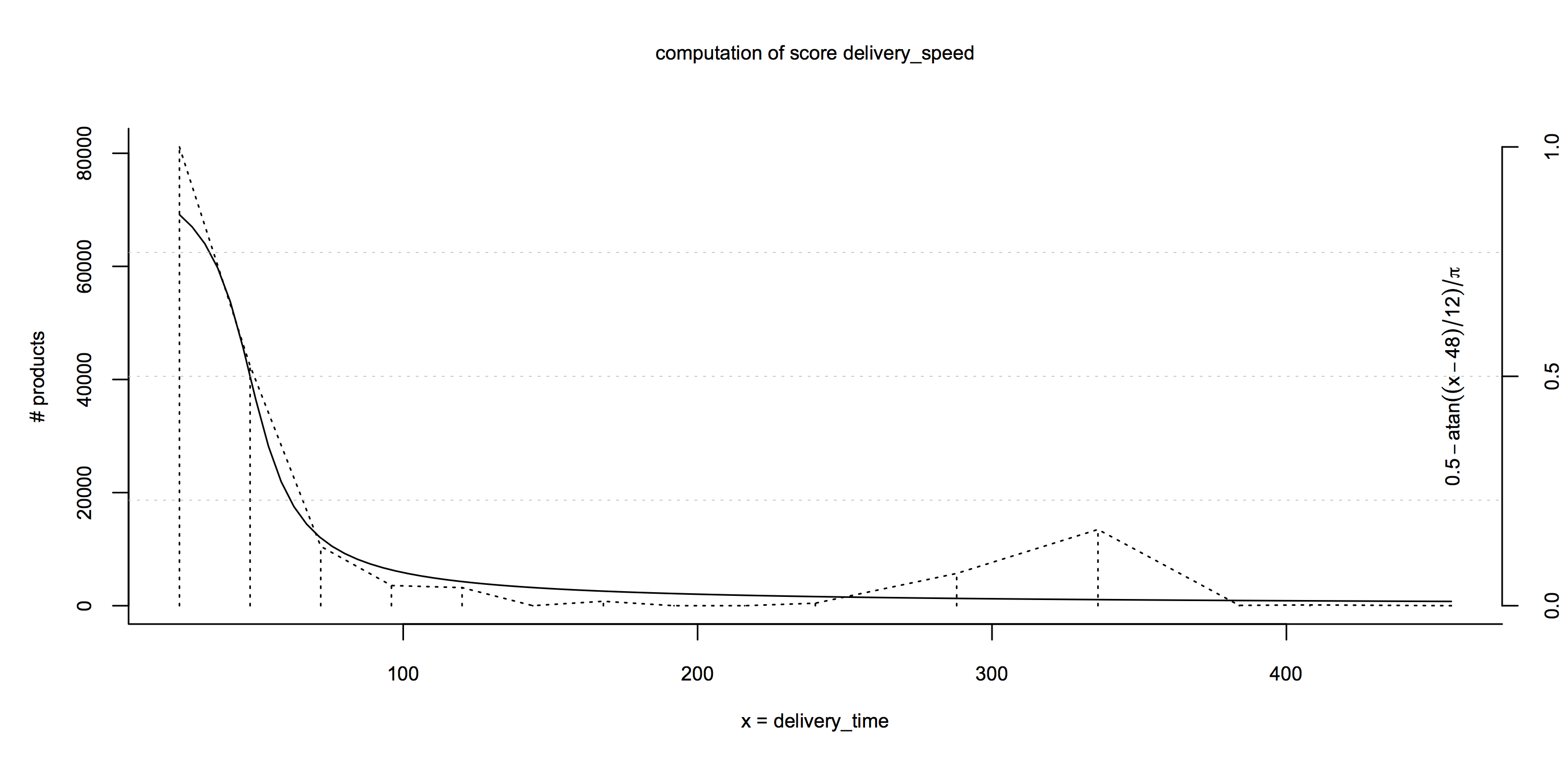
Here our stakeholders made a conscious decision to define 48 hours as the neutral case (a score of 0.5) and everything after 60 hours as “bad”: 0.5 - atan((x - 48) / 12) / π.
Finally, a word on data processing: We compute these scores as part of the ETL / data integration processes of the data warehouse. Given a table search_tmp.product_search_score_kpi which contains a list of performance measures per product, computing normalized scores can be as easy as this (most computations are left out due to their sensitive nature):
CREATE TABLE search_next.product_search_score AS
SELECT
merchant_product_id,
round((atan(number_of_sold_items
/ (SELECT avg(number_of_sold_items)
FROM search_tmp.product_search_score_kpi
WHERE number_of_sold_items > 0))
/ (0.5 * pi())) :: NUMERIC,
2) AS top_seller,
CASE WHEN number_of_impressions = 0 THEN 0
ELSE
round((atan(power((number_of_impressions :: NUMERIC + 20) / 2.5, 0.7)
/ (SELECT min(number_of_impressions)
FROM search_tmp.product_impression
WHERE pct_rank > 0.90))
/ (0.5 * pi())) :: NUMERIC,
2) END AS pdp_impressions,
round((0.5 - atan((delivery_time - 48.) / 12.)
/ pi()) :: NUMERIC,
2) AS delivery_speed,
round(random() :: NUMERIC, 2) AS random
FROM search_tmp.product_search_score_kpi;
But even without a data integration infrastructure in place, it should be quite easy to collect relevant metrics and translate them into scores. Since none of these numbers (except the random score) changes very quickly, it is sufficient if they are computed once a night.
Especially in businesses with a B2B focus, customers expect to get discounts after they have been using the service/website for a longer period of time. The search infrastructure should be able to handle such use cases and customers should be able to see their own discounted prices while browsing the catalog. Luckily, Elasticsearch enables us to extend basic filtering, aggregation and fetching functionalities with scripts that are executed within the document context and can be used instead of fixed document values.
In this example, we have a script with two customer-based parameters: fixed prices (one per product ID) and category discount levels. These parameters are passed to the Elasticsearch query only for logged-in customers with granted discounts.
{
"query": {
"script_fields": {
"final_gross_price_discount": {
"script": "if (fixed_prices && fixed_prices[doc['sku'].value]) {return fixed_prices[doc['sku'].value]}; if(!discounts) {return}; def discount = 0; for (String i : doc['discount_categories']) {if(discounts[i] && discounts[i].value > discount) {discount = discounts[i].value}}; if (discount > 0 && doc['prices.discount_gross_price_level_' + discount].value) {return doc['prices.discount_gross_price_level_' + discount].value}",
"params": {
"discounts": {
"47": 5,
"453": 2,
"305": 7
},
"fixed_prices": {
"210417044": 9999,
"128553": 100
}
}
}
}
}
}
As a result, customers see personalized prices. In a similar way, it’s possible to build filters and price facets based on dynamically calculated prices.
Finally, we want to provide you with a list of some additional and potentially useful principles regarding the setup of an on-site search experience.
Each document we put in Elasticsearch corresponds to an URL (note that the mapping type in our schema is called page, not product or something else). We do this because we think that different page types (for example brand pages, category pages, CMS pages) can be relevant for the same search. There is no reason why somebody interested in shipping prices should not be able to find corresponding information using the search bar of a website (unfortunately this is rarely the case)–so we put it in the same index as products, using the same document structure:
{
"type": "cms-page",
"search_result_data": {
"id": "7",
"title": "Versandkosten | hammer2000.de",
"name": "Versandinformationen",
"url": "/versandkosten"
},
"search_data": {
"full_text_boosted": [
"Versandinformationen"
],
"full_text": [
"<p>Die Versandkosten innerhalb Deutschlands betragen 5,95€ pro Bestellung. Ab einem Warenwert von %freeShippingPrice% liefert Hammer2000 versandkostenfrei.</p><p>Hammer2000.de liefert im Moment nur nach Deutschland.</p> <p>Die Versandkosten innerhalb Deutschlands betragen 5,95€ pro Bestellung. Ab einem Warenwert von %freeShippingPrice% liefert Hammer2000 versandkostenfrei.</p><p>Hammer2000.de liefert im Moment nur nach Deutschland.</p>"
]
}
}
Furthermore, our generic page-based schema allows for other search operations such as rendering a “staple page” (an overview of different variants of a product; often with their own facet navigation such as the aforementioned Senkkopf-Holzbauschraube):
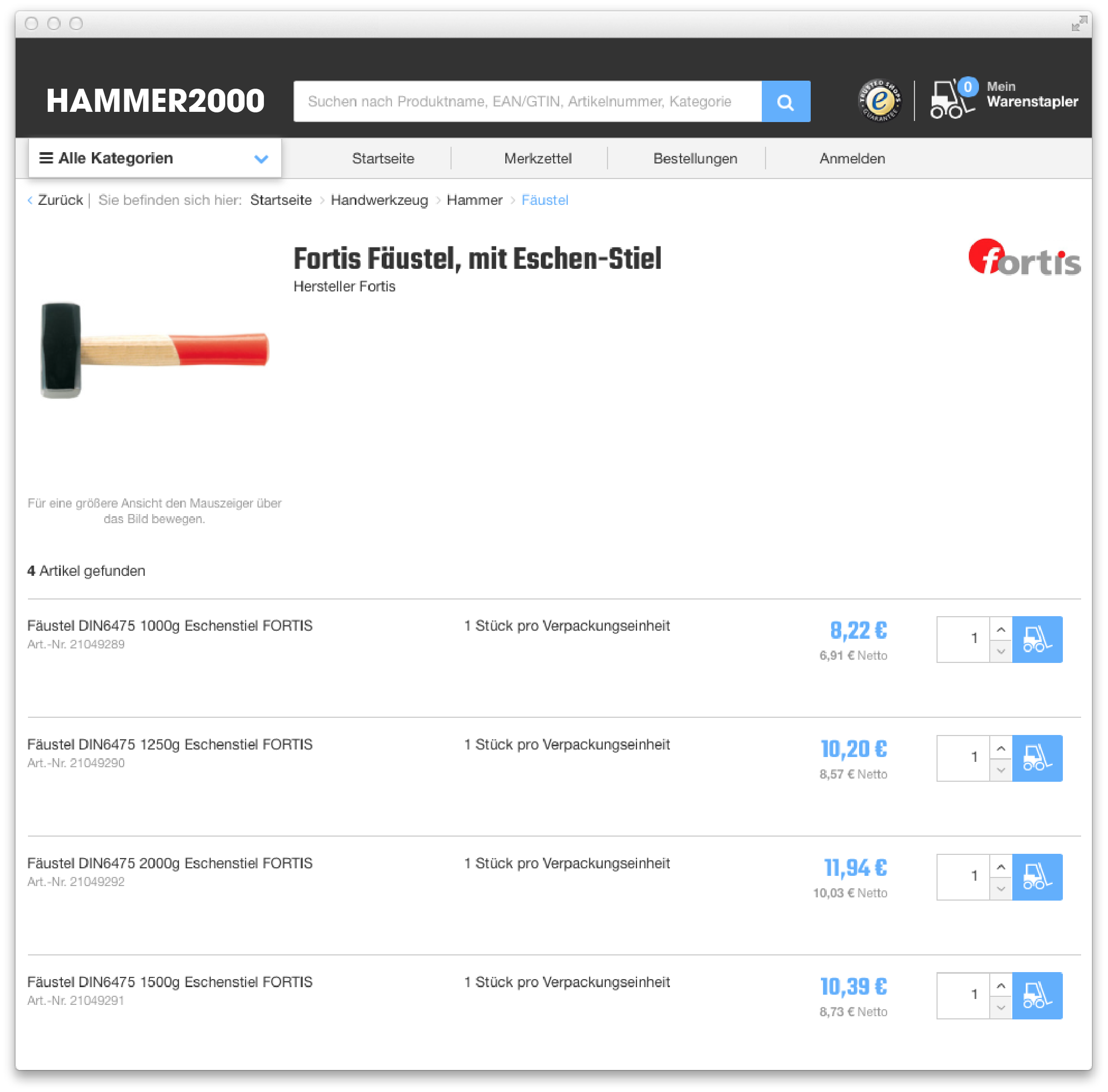
The query looks very similar to a normal faceted navigation, except that it searches only within a specific staple.
An usage-driven search schema and document structure puts more burden on importers because document attributes have to be duplicated in multiple fields with varying formats. To handle this additional complexity (and to keep the import code maintainable), we recommend to explicitly decide which attributes to put in which field; ideally as data (for example in a database table and ideally as part of an already existing attribute management system):
| attribute | full text | full text boosted | string facet | number facet | completion terms | suggestion terms | search result data |
|---|---|---|---|---|---|---|---|
description |
✓ | ||||||
manufacturer |
✓ | ✓ | ✓ | ✓ | ✓ | ||
name |
✓ | ✓ | ✓ | ✓ | |||
sku |
✓ | ✓ | |||||
hammer_weight |
✓ | ✓ | ✓ | ||||
hammer_handle_length |
✓ | ✓ | |||||
hammer_handle_material |
✓ | ✓ | ✓ | ||||
preview_image |
✓ | ||||||
url |
✓ |
Bonus points for providing a user interface for this purpose. It would allow category or product managers to make fine-grained conscious decisions on how to use certain attributes in search. For example, a numeric attribute hammer_weight could be used as a string facet and completion term, whereas another numeric attribute hammer_handle_length would only be used as a number facet.
Everybody has an opinion on how search should work, and being a product owner / product manager for search is definitely not the easiest task.
What is good product management for search? Certainly it is not of technical nature (“please use technique X”, these suggestions usually suck). Rather helpful are concrete examples of expected and actual behaviour from a user perspective (“If I search for a hammer, I want to find a hammer”).
This is an excerpt of the actual input we got from various stakeholders at Hammer2000:
| search term | issue / expected result | dev comment |
|---|---|---|
| makita | I would expect standard power tools on top (e.g., drilling machines), not a jacket and a laser | Enhance WHF |
| akkuschrauber | I would expect more search word suggestions, not just Akkuschrauber-Set | PM: In specification |
| schleifscheibe | No top sellers on top | Add all categories, add popularity score to category ranking |
| latt hammer | Decompounder (I believe) not working correctly–should return Latthammers first | Decompunder works perfect, but we might need to recalibrate the search a little bit |
| blindnietwerkzeug | Only returns products called “Blindnietwerkzeug” but no Blindnietzange or Blindnietmutter-Handgerät and so on | Please add tokens to list |
| bohrmaschine bosch | Top categories should be the ones that actually have “Bohrmaschine” as their name, not Bohrständer and stuff like that | Fixed |
| tiefenmesschieber | Customers missing an “s” don’t get any results for TiefenmesSschieber | Very hard to fix |
| bügelmessschraube | Doesn’t find the right products because products are abbreviated as “Bügelmessschr.” | Product data issue |
| klopapier | Synonym for “Toilettenpapier” | Please set up synonyms yourself |
| duebel | Doesn’t find products when “ä” is “ae”–that should work for all Umlaute | Fixed |
| Fein | Fein electronics, since they are an A brand | There is a ticket for manufacturer boost in the backlog |
| Handwaschpaste | Doesn’t find category | bug |
A final remark: Search problems are very often data quality problems. Search cannot fix issues of missing attributes, bad product descriptions or wrong categorizations. In general: the better the underlying document material, the better the search experience.
This document contains quite a lot of things that we thought to be useful for others who try to build an on-site search. If you have to take one thing home from this, then it’s the importance of doing something like our usage-driven schema & document structure.
If you have comments, suggestions or corrections, feel free to leave them below.